实例场景 我们有一个golang编写的服务,由于比较奇葩的业务需求,要预装载大概500W左右的redis key到内存,其中服务的每次请求大概会需要用到500W之中的90W左右的key,但是这用到90W的key不是一次使用, 是因服务的具体逻辑而不固定什么时间使用, 不固定每次使用的key数量大小,但是总共需要是两万key左右。服务请求的逻辑执行到某个点时,需要重新从redis装载大概四百万的key,替换原来的老的key。
[...]从前现在过去了再不来
实例场景 我们有一个golang编写的服务,由于比较奇葩的业务需求,要预装载大概500W左右的redis key到内存,其中服务的每次请求大概会需要用到500W之中的90W左右的key,但是这用到90W的key不是一次使用, 是因服务的具体逻辑而不固定什么时间使用, 不固定每次使用的key数量大小,但是总共需要是两万key左右。服务请求的逻辑执行到某个点时,需要重新从redis装载大概四百万的key,替换原来的老的key。
[...]
关于go的协程调度, GMP的理解总结,理解不到位请指正,谢谢。
GOMAXPROCS只要是设置P的值, 而每一个P都要对应一个M, 当P发生阻塞时,又没有空闲的M的时候, 这个时候系统会生成新的M, 那么M就会大于P的数量, 所以go的runtime,M和P的数量上看, 是会 M >= P。
M是系统线程, 系统运行时, 是要根据M来切换上下文的, 也就是说,M的数量越多的时候,切换上下文次数就会越多,就会越耗时, 这个切换是CPU计算的切换,不是IO的切换。
那么我们就可以得出结论了, 当程序是IO密集型的时候,我们会进行网络IO, 文件IO等等,这种程序不会造成太多CPU的计算切换,所以这种请况下,我们设置比常规默认更多的GOMAXPROCS可以增加程序处理的P[...]
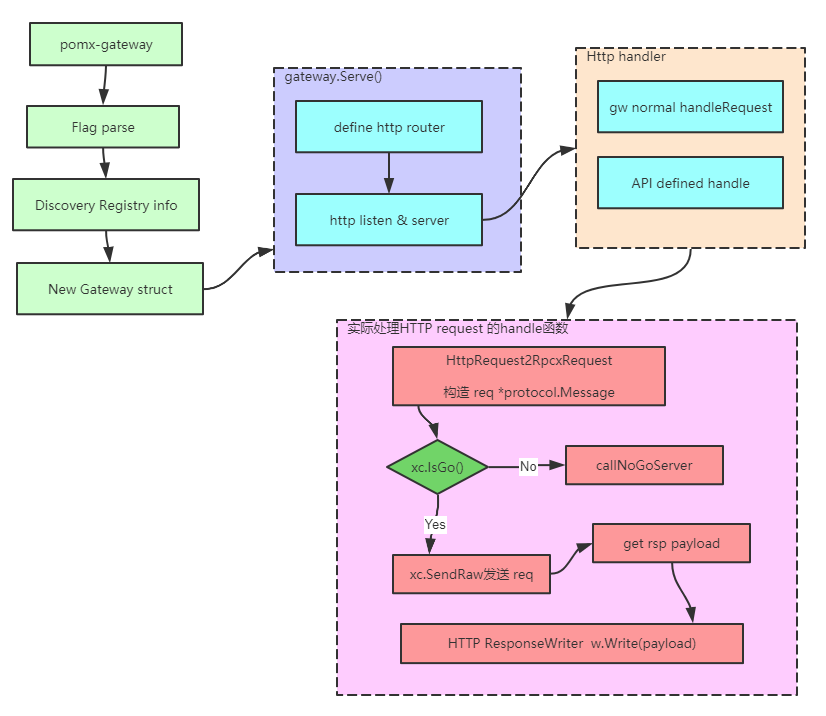
功能实现 - API define handle 让网关支持自定义路由, 可以根据自定义的理由,网关直接调用相应的服务,直接是二层服务的架构,减少客户端(消费者)这一层程序
// 关键代码
router.POST("/echo", g.EchoHandle) // 消费echo服务
func (g *Gateway) EchoHandle([...]
拥抱变化这句话,相信大家都有不同的理解,我这里也分享一下我的看法。
以前我是这样理解这句话的,简要来说就是“等要变化的时候我才去拥抱”,举个例子,比如在公司上班,等到公司业务不行了,项目要腰斩了,直到这份工作保不住了,需要寻找新的工作了,这个时候才意识到,我要变化了。然后开始寻找新的机会,开始为新的去处而做准备。
经过一些事之后,我对这句话有了新的认识。首先拥抱变化的本质我有了新的理解,这句话的本质是什么呢?套用我们软件架构的一个理念,总结来说就是扩展性好,从而达到高可用的效果,19年相信在天朝的程序员们或多或少都感觉到丝丝寒潮,996,35大限这些词会在一些自媒体中每每出现,偶然思考,可能会意识[...]
日常中用的生产者,消费者程序都是阻塞实时消费的, 跟golang的channel处理机制是一样的,所以用channel来实现可以说是天然合适,这里用golang来写一个范例
package golang_in_action
import (
"fmt"
"sync"
"testing"
"time"
)
func dataProducer(ch chan int, wg *sync.WaitGroup) {
go func() {
for i := 0; i < 10; i++ {
[...]
python的try, except 很给力, 在有一些需要捕捉异常的场景下,能够安装异常的类别来进行特定的操作,假如说现在我们有一个场景是“无论产生什么异常,我们都有一个总的捕捉逻辑,这种情况下,我们就要注意try的闭包作用域问题了
def allCatch(func):
def wrapper(*args, **kwargs):
try:
ret = func(*args, **kwargs)
return ret
except Exception as e:
print "[allcatch] -----------[...]
当我们要进行redis操作或者其他中间件操作的时候,为了少发起服务端的连接,我们会在main函数外先建立连接,以减少服务端的连接次数
事实上,很多中间件的连接只是一个语法声明,其实并没有进行真正的连接,比如下面的代码
package main
import (
"fmt"
"github.com/garyburd/redigo/redis"
"github.com/spf13/cast"
"math/rand"
"time"
)
var (
rds, errxx[...]
我们在写协程程序的时候,经常会碰到一个场景就是我们要分发执行任务给不同的goroutine(简称gor),然后再把各个gor的处理结果汇总起来,这个时候就要注意gor的数据污染问题,我们可以通过闭包来防范各个gor之间的数据污染
下面的一个gor之间数据互相污染的范例
func main() {
setMem := make(map[int]int)
wg := sync.WaitGroup{}
lk := sync.RWMutex{}
for i := 0; i < 10; i++ { // 1
wg.Add(1)
go fun[...]
在实际的日常开发中,按照场景来考虑golang的并行编程模型是比较合适的一种做法, 这样既避免了空谈,又能清晰易懂,代入感比较强
比如现在我们有一个程序,是要请求很多URL,只要每个协程能发出请求便可,没必要验证请求结果和请求进行时设置数据,或者通信数据, 这种场景因为没有涉及到数据流的走向,所以用WaitGroup比较合适
var wg sync.WaitGroup
func ReqUrl() {
// 请求URL
defer wg.Done()
}
func main() {
urlCout := 10
for i := 0; i[...]