继上一篇《Mysql 事务探索及其在 Django 中的实践(一)》交代完问题的背景和 Mysql 事务基础后,这一篇主要想介绍一下事务在 Django 中的使用以及实际应用给我们带来的效率提升。
首先贴上 Django 官方文档中关于 Database Transaction 一章的介绍:https://docs.djangoproject.com/en/1.9/topics/db/transactions/。
在 Django 中实现事务主要有两种方式:第一种是基于 django ORM 框架的事务处理,第二种是基于原生地执行 SQL 语句的 transaction 处理。
基于 django ORM 框架的事务处理
默认情况下,django 的事务处理是自动提交(auto-commit),即在执行 model.save(),model.delete() 时,所有的改动会被立即提交,相当于数据库设置了 auto commit,没有任何隐藏的 rollback。
在网上查了一些资料,了解到 django 手动配置事务的方式主要有三种:第一种是将一个 http request 的所有数据库操作包裹在一个 transaction 中,第二种是通过 transaction 中间件对 http 请求的事务拦截,第三种是自己在 view 中通过装饰器灵活控制事务(我们的平台最后用的就是这一种)。
1. 将一个 http request 的所有数据库操作包裹在一个 transaction 中
这种方式配置非常简单,只需要在 settings.py 中的 database 配置中加入‘ATOMIC_REQUESTS’: True 即可。如图 1 所示:
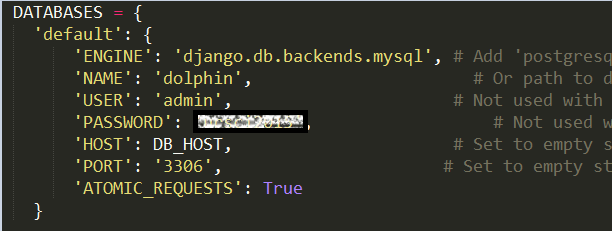
图 1 Database 中加入’ATOMIC_REQUESTS’:True
通过这种配置,django 在调每个 view 方法之前会开始一个事务,当且仅当该响应没有任何问题,django 才会提交这个事务;如果 view 中出现了异常,则 django 会回滚该事务。这样做的好处显而易见,就是安全简便,但是随着网站的流量变大,如果每个 view 被调用时都打开一个事务就会变得有点繁重,从而会降低网站的效率。它对性能的影响取决于你的应用的查询效率以及你的数据库处理锁的能力。此外,使用这种方式,回退的只是数据库的状态,而不包括其他非数据库项的操作,例如发送 email 等。
2. 通过 transaction 中间件对 http 请求的事务拦截
配置方法是在 settings.py 中配置 MIDDLEWARE_CLASSES,如图 2 所示:
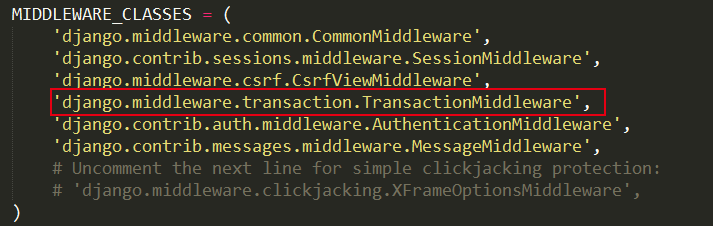
图 2 transaction 中间件配置
需要注意的是,这样配置之后,与你中间件的配置顺序是有很大关系的。在 TransactionMiddleware 之后的所有中间件都会受到事务的控制。但 CacheMiddleware,UpdateCacheMiddleware,FetchFromCacheMiddleware 这些中间件不会受到影响,因为 cache 机制有自己的处理方式,用了内部的 connection 来处理。另外 TransactionMiddleware 只对默认的数据库配置有效,如果要对另外的数据连接用这种方式,必须自己实现中间件。(此处必须声明,对于这种方法,本人没有仔细研究过,只是借鉴了一下网上的资料)
3. 自己在 view 中通过装饰器灵活控制事务
最后种方式,通过装饰器灵活配置,也是我们平台最后采用的方式。
1)@transaction.autocommit
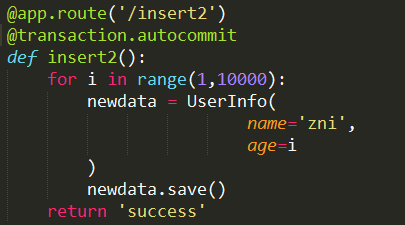
django 默认的事务处理,采用此装饰模式这种方式可以忽视全局的 transaction 配置。
2)@transaction.commit_on_success
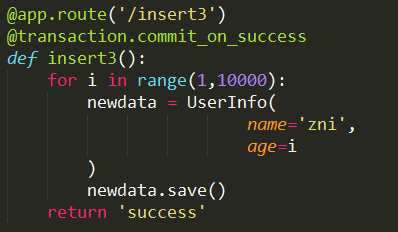
采用此装饰模式,当此方法的所有工作完成后,才会提交事务。
3)@transaction.commit_manually
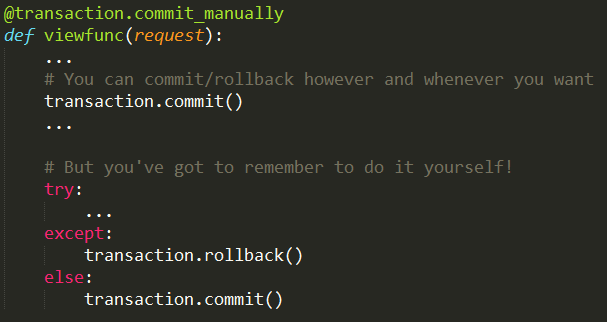
采用这种方式,你可以自由地随意提交或回滚事务,完全自己处理。如果没有调用 commit() 或 rollback(),则程序会抛出 TransactionManagementError 异常。
基于原生地执行 SQL 语句的 transaction 处理
再来讲讲 Django 中第二种事务处理方式,即用原生地执行 SQL 语句的方式。
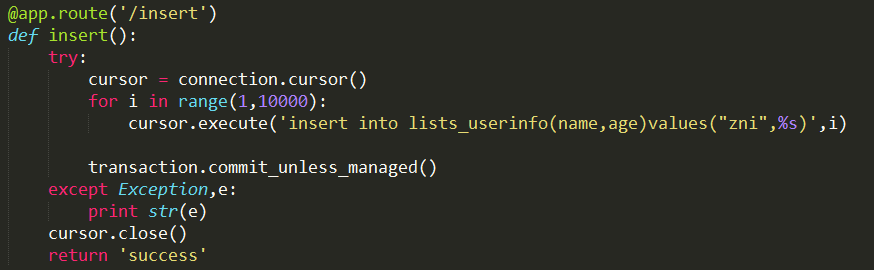
图 3 原生地执行 SQL 语句中的事务处理
这种处理方式比较简单,以图 3 中的方法为例,首先定义了一个游标 cursor,通过 cursor 任意地执行 sql 语句,最后通过 transaction.commit_unless_managed() 来提交事务。
延伸
上面介绍了 Django 中的两种事务处理的方式,到这里我突然想到一个问题:
如果一个方法中既包含了装饰器 @transaction.commit_on_success,又执行了原生 SQL 语句的事务提交,当方法出现异常导致事务回滚时,原生的 SQL 语句所提交的事务会不会被回滚?
为了验证这个问题,我用 Flask 写了两个接口来进行验证:
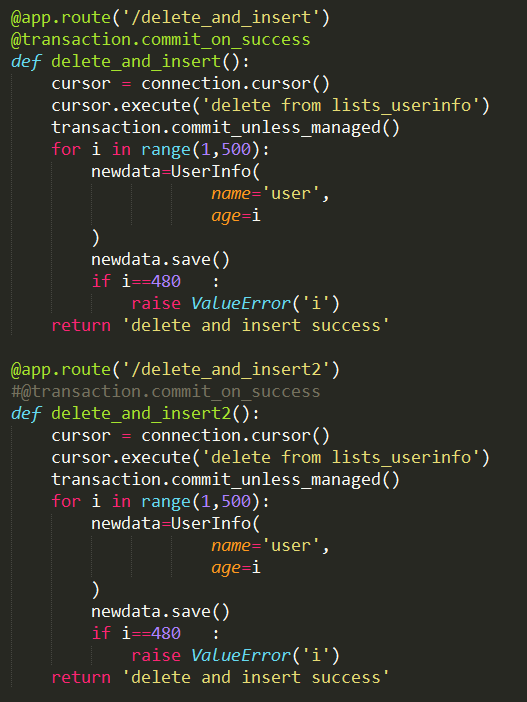
接口 delete_and_insert 和接口 delete_and_insert2 都是先通过 cursor 事务提交执行清除表,然后往表里循环插入数据,当满足条件 i=480 的时候,抛出一个 ValueError。唯一的区别就是接口 1 中采用了装饰器 @transaction.commit_on_success,而接口 2 中没有。实际执行发现:
1. 在调接口 1 时,原数据库表中的数据不会变化,说明通过 cursor 执行清除表的操作也会回滚。
2. 在调接口 2 时,原数据库表中的数据被删除,数据库留下的是新的数据:所有的 name 都为 user,而 age 从 1 到 480。
从而证明,当 view 方法加了装饰器 @transaction.commit_on_success 后,即使 view 中使用了 cursor 执行原生 sql 语句,并执行了 transaction.commit_unless_managed(),但是如果 view 中有异常抛出,整个 view 方法的内容都会回滚。
实际应用
最后,回归最初的问题本身,当我把事务应用到我们平台的后台接口中后,发现了一个意外的惊喜:接口 A 的执行时间从原来的 5-10 分钟一下子缩短到了几秒钟就完成了。欣喜之余仔细思考了一下才觉得性能显著提升的原因应该是:在应用事务之前,所有 SQL 语句都是自动提交的,每插入一条数据,数据库表的索引可能就需要重建一次,当大量的 sql 语句逐一插入时,数据库表的索引就需要不断地重建,其中就需要耗费大量的时间。而在应用事务之后,所有的插入是一次性提交,数据库表的索引只需要重建一次,大大减少了开销。
这也验证了数据库的索引不是万能的,合理的建立索引确实能大大地优化查询速度,因为索引的存储结构就像一本字典一样,我们在查找某个特定的字时会根据拼音的首字母的方式先找到该字的第一个字母所在页数,然后直接跳到那一页往后去翻。然而这也决定了字典在初始存储这些字时就需要根据这些字的特点将每个字放在特定的存储位置。当有新的字加入时,为了插入到特定的位置,就必须重新建立映射关系。
补充:合理建立索引
下面是我工作中搜集的一些关于索引建立的规则,也欢迎大家参考,指正:
1. 搜索的索引列 最适合索引的列是出现在 where 子句种的列,或连接子句中指定的列。 而不是 select 关键字后的选择列表的列。 2. 使用唯一索引 索引的列的基数越大,索引效果越好。比如 id 每行都不同,出生日期也不太相同,适合作索引。 而性别男或女只有两者情况,即使加索引,不管搜索哪个值都会得出大约一半的行。 3. 使用短索引 例如对字符串列进行索引,应该制定一个前缀长度。比如一个 CHAR(200) 的列,如果前 10 或 20 个字符内就大不相同,则可以只对前 10 个或 20 个字符进行索引。节省大量索引空间,也使查询更快,涉及的磁盘 IO 较少。较短的键值,索引高速缓存中的块能容纳更多的键值。 4. 不要过度索引 每个额外的索引都要占用额外的磁盘空间,降低写操作的性能。因为在写修改表的内容时,索引必须进行更新,有时可能需要重构。 就比如一本字典,加入新的字必须要根据目录插入指定位置,后面的内容都要更新。 5. 选择最常作为访问条件的列作为主键 InnoDB 有一个默认的保存顺序,按照主键或内部列进行访问的速度是最快的(比唯一索引还要快)。
本文链接:https://www.pangulab.com/post/496191ac.html, 参与评论 »
--EOF--
发表于 2019-01-11 06:21:16 ,并被添加「 python 、 django 」标签。
本站使用「署名 4.0 国际」创作共享协议,转载请注明作者及原网址。更多说明 »
提醒:本文最后更新于 1932 天前,文中所描述的信息可能已发生改变,请谨慎使用。
专题「web开发」的其它文章 »
- python gevent实践应用范例 (Apr 05, 2019)
- BSON与JSON的区别 (Feb 10, 2019)
- 解释pykafka参数最详细的记录 (Jan 30, 2019)
- python 操作Kafka (Jan 22, 2019)
- gRPC 中 Client 与 Server 数据交互的 4 种模式 (Jan 19, 2019)
- 从Protocol Buffers 到 gRPC (Jan 15, 2019)
- Python编程reload热更新代码 (Jan 10, 2019)
- 理解 JWT(JSON Web Token)认证及 python 实践 (Jan 08, 2019)
- 分布式队列神器 Celery - Python (Jan 08, 2019)
- 通过flask的request对象获取url (Jan 07, 2019)
- Flask Restful API 权限管理设计与实现 (Jan 03, 2019)
- 使用 Flask 设计带认证 token 的 RESTful API 接口 [翻译] 使用 python 的 Flask 实现一个 RESTful API 服务器端 (Jan 03, 2019)
评论列表